

Introduction
🌐 AWS Lambda@Edge is a powerful tool that allows you to run serverless code at the edge of the Amazon CloudFront content delivery network (CDN), significantly reducing latency and improving performance. In this guide, we will delve into the key aspects of managing Lambda@Edge functions, including configuration access, region-specific settings, environment variables, and timeout limits.
Accessing Lambda@Edge Configuration from Edge Locations
📍 When setting up a Lambda@Edge function, it’s crucial to understand that all configuration data, including tags, environment variables, memory, and timeout settings, are stored in the us-east-1 (North Virginia) region. Here’s what this means for your setup:
- Configuration Storage in us-east-1: Even though Lambda@Edge replicates the function code to edge locations worldwide, the configuration details are not replicated to other regions. You need to ensure your Lambda@Edge function has the right permissions to read this data from us-east-1.
- Permissions for Accessing Configuration: Include
lambda:GetFunctionConfigurationin your IAM policy and set the region tous-east-1when calling for configurations.
const AWS = require('aws-sdk');
const lambda = new AWS.Lambda({ region: 'us-east-1' });
async function getFunctionConfig(functionName) {
const params = { FunctionName: functionName };
try {
const config = await lambda.getFunctionConfiguration(params).promise();
console.log("Function configuration:", config);
return config;
} catch (error) {
console.error("Error retrieving function configuration:", error);
throw error;
}
}
// Usage
getFunctionConfig('your-function-name');Execution in Edge Regions
🌍 Although Lambda@Edge functions are managed and configured in us-east-1, they execute in AWS regions closest to the CloudFront edge locations that received the request. This setup enables faster processing and reduces latency. For example, a user in India would have their request routed to the nearest edge location, and the Lambda@Edge function would execute in an AWS region like Mumbai.
Limitations with Environment Variables
🚫 One significant limitation of Lambda@Edge is that it does not support environment variables. Here are some workarounds:
- Use SSM Parameter Store: Store configuration values in AWS Systems Manager (SSM) Parameter Store and retrieve them at runtime. However, this adds slight latency due to cross-region requests if your function executes outside
us-east-1. - Hardcode or Pass Config Values: If security and flexibility permit, consider hardcoding certain values directly in the function or passing them through the event itself.
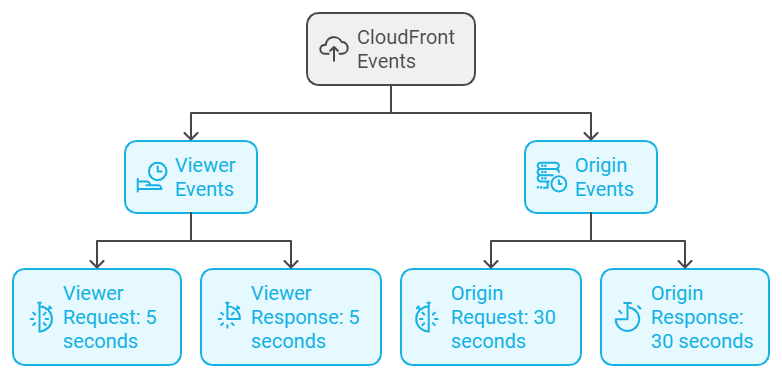
Understanding Lambda@Edge Function Timeout Limits by Event Type
⏱️ AWS Lambda@Edge functions have different timeout limits based on the CloudFront event type that triggers the function. Here’s a breakdown:
- Viewer Request and Viewer Response Events: Maximum Timeout – 5 seconds
- Use Case: These events are triggered when CloudFront receives a request from or sends a response to the viewer.
- Origin Request and Origin Response Events: Maximum Timeout – 30 seconds
- Use Case: These events are triggered when CloudFront forwards a request to or receives a response from the origin server.
Choosing the Right Timeout
If your Lambda@Edge function involves light processing, like request validation, use Viewer Request or Viewer Response events with their 5-second limit. For more complex tasks, such as content customization or origin request modifications, use Origin Request or Origin Response events that allow up to 30 seconds.
Handling Redirects with Lambda@Edge
🔄 Redirects are essential when you need to migrate URLs or use vanity URLs. Here’s how you can handle redirects using Lambda@Edge:
Scenario 1: Redirections for Campaign URLs
Suppose you want to set up a friendly short URL for a campaign and redirect it to the actual landing page without changing the origin server configuration. You can use an Origin-Request Lambda trigger to set up this redirection.
- Viewer Request: The viewer makes a request for a URL.
- Cache Check: If the resource is cacheable and available in the cache, it is returned from the CloudFront Edge location.
- Origin-Request Lambda: On a cache miss, the Lambda function intercepts the request and checks for redirection rules. If a rule matches, it generates a permanent redirection (HTTP 301 status code) which is cached by CloudFront and returned to the viewer.
Example Code Snippet for Origin-Request Lambda
// Viewer makes a request for a URL.
// If the requested resource is cacheable and available in the cache, it is returned from CloudFront Edge location.
// If the resource is not cacheable or not present in the cache, CloudFront fetches the object from the origin.
exports.handler = async (event) => {
const request = event.Records.cf.request;
const uri = request.uri;
// Check if the URI matches a redirection rule
if (uri === '/old-url') {
const response = {
status: '301',
statusDescription: 'Moved Permanently',
headers: {
location: [{ key: 'Location', value: '/new-url' }]
}
};
return response;
}
// Pass through the request if no redirection rule matches
return { status: '200', statusDescription: 'OK' };
};URL Rewriting with Lambda@Edge
🔄 URL rewriting is another powerful feature of Lambda@Edge, especially useful for single-page applications (SPAs) and pretty URLs.
Viewer Request vs. Origin Request
You can trigger Lambda@Edge functions on either Viewer Request or Origin Request events:
- Viewer Request: This event happens before CloudFront checks the cache. It’s useful for universal URL rewrites but involves invoking the Lambda function on every request.
- Origin Request: This event occurs on a cache miss, right before fetching from the origin. It maximizes cache hits and reduces the number of Lambda invocations.
Example for URL Rewriting
Here’s an example of rewriting URLs for an SPA using the Viewer Request event:
exports.handler = async (event) => {
const request = event.Records.cf.request;
const uri = request.uri;
// Rewrite the URL to point to the index.html
if (uri === '/adams') {
request.uri = '/index.html';
}
return { status: '200', statusDescription: 'OK' };
};Dynamically Routing Viewer Requests
📍 You can also use Lambda@Edge to dynamically route viewer requests to different origins based on various request attributes such as headers, query strings, and cookies.
Example for Dynamic Routing
Here’s how you can set up a Lambda function to route requests based on the viewer’s country:
exports.handler = async (event) => {
const request = event.Records.cf.request;
const headers = request.headers;
// Determine the origin based on the viewer's country
if (headers['cloudfront-viewer-country'] && headers['cloudfront-viewer-country'].value === 'US') {
request.origin = { custom: { domainName: 'us-origin.example.com', port: 80, protocol: 'http', path: '', sslProtocols: ['TLSv1.2'], readTimeout: 5, keepaliveTimeout: 5 } };
} else {
request.origin = { custom: { domainName: 'intl-origin.example.com', port: 80, protocol: 'http', path: '', sslProtocols: ['TLSv1.2'], readTimeout: 5, keepaliveTimeout: 5 } };
}
return { status: '200', statusDescription: 'OK' };
};Key Takeaways for Optimizing Lambda@Edge Functions
📝 Here are some best practices to ensure efficient performance and reliable access to configuration details with Lambda@Edge:
- Set the Lambda client’s region to us-east-1 when accessing function configuration.
- Review IAM role permissions carefully to include the
lambda:GetFunctionConfigurationaction with a focus on theus-east-1region. - Select the correct CloudFront event type based on processing requirements and timeout limits.
- Use alternative methods for configuration management since environment variables are not supported in Lambda@Edge.
FAQ
What is the primary region for storing Lambda@Edge function configurations?
The primary region for storing Lambda@Edge function configurations is us-east-1, regardless of where the function executes.
Why are environment variables not supported in Lambda@Edge?
Environment variables are not supported in Lambda@Edge due to the nature of how these functions are executed across different edge locations. Instead, use alternatives like AWS Systems Manager (SSM) Parameter Store or hardcode/config values within the function.
What are the different CloudFront events that can trigger a Lambda@Edge function?
Lambda@Edge functions can be triggered by four different CloudFront events: Viewer Request, Origin Request, Origin Response, and Viewer Response.
How can I handle redirects using Lambda@Edge?
You can handle redirects using Lambda@Edge by setting up either Viewer Request or Origin Request triggers. These functions can check for redirection rules and generate HTTP 301 or 302 status codes accordingly.
What are the benefits of using Lambda@Edge for URL rewriting and redirects?
The benefits include offloading redirect logic from the origin, central management of redirects, and lower latency responses to end users. Additionally, it maximizes the use of CloudFront cache and reduces the cost associated with subsequent Lambda function executions.
For more detailed information on getting started with AWS Lambda@Edge and Amazon CloudFront, refer to the AWS Documentation.
Next : AWS CloudFront: The Ultimate Guide to Supercharging Your Web Performance 🚀





1 thought on “Mastering AWS Lambda@Edge: A Comprehensive Guide to Configuration, Redirects, and Optimizations”