
![Distributed Caching Deep Dive: From Basics to Best Practices [Updated]](https://devnotes.tech/wp-content/uploads/2024/11/distributed-caching.jpg "Distributed Caching Deep Dive: From Basics to Best Practices [Updated]")
Hey there, fellow tech enthusiasts! After spending over a decade building and scaling applications, I’ve learned that caching is like having a good coffee machine in the office – you don’t realize how essential it is until you’ve experienced life without it. Let’s dive into the world of distributed caching, a crucial component powering most of the apps you use daily.
What is Distributed Caching? 💡
Think of distributed caching as having multiple mini-fridges spread across different office locations instead of one giant fridge. Data is stored across multiple nodes, providing:
- Faster access times ⚡
- Better scalability 📈
- Improved fault tolerance 🛡️
- Reduced database load 🎯
Distributed Caching Strategies: The Complete Guide 🎯
1. Cache-Aside (Lazy Loading)
The “I’ll get it when I need it” approach
def get_user_data(user_id):
# Try cache first
user = cache.get(user_id)
if user is None:
# Cache miss - get from database
user = database.get_user(user_id)
# Store in cache for future requests
cache.set(user_id, user, expire=3600)
return user
Best For: Read-heavy applications where data freshness isn’t critical
Real-World Use: Social media profile data, product catalogs
2. Write-Through 📝
The “better safe than sorry” strategy
def update_user_data(user_id, data):
# Update database first
database.update_user(user_id, data)
# Then update cache
cache.set(user_id, data, expire=3600)
Best For: Applications requiring data consistency
Real-World Use: Financial transactions, inventory systems
3. Write-Behind (Write-Back) ⚡
The “I’ll do it later” approach
class WriteBackCache:
def update_data(self, key, value):
# Update cache immediately
self.cache.set(key, value)
# Queue database update
self.update_queue.put((key, value))
async def process_updates(self):
while True:
key, value = await self.update_queue.get()
try:
await self.database.update(key, value)
except Exception:
self.retry_queue.put((key, value))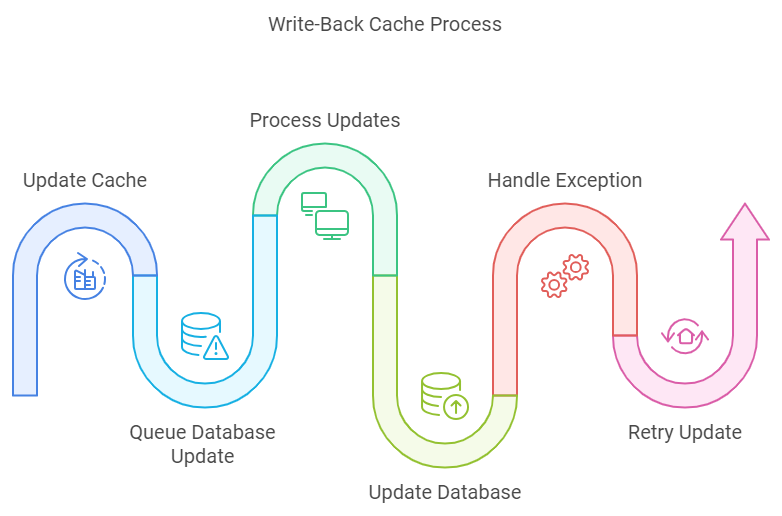
Best For: Write-heavy applications tolerant of eventual consistency
Real-World Use: Logging systems, analytics platforms
4. Read-Through 📚
The “transparent reading” strategy
class ReadThroughCache:
def get_data(self, key):
data = self.cache.get(key)
if data is None:
data = self.load_from_database(key)
self.cache.set(key, data)
return data
Best For: Applications needing abstracted cache management
Real-World Use: Content delivery systems, blog platforms
5. Refresh-Ahead 🔄
The “predictive refresh” strategy
class RefreshAheadCache:
def __init__(self, refresh_threshold=0.5):
self.refresh_threshold = refresh_threshold
def get_data(self, key):
data, metadata = self.cache.get_with_metadata(key)
if self.should_refresh(metadata):
asyncio.create_task(self.refresh_cache(key))
return data
Best For: Applications with predictable access patterns
Real-World Use: News feeds, gaming leaderboards
6. Multi-Level Caching 🎭
The “layered defense” strategy
class MultiLevelCache:
def get_data(self, key):
# Check L1 cache (local/in-memory)
data = self.l1_cache.get(key)
if data:
return data
# Check L2 cache (distributed)
data = self.l2_cache.get(key)
if data:
self.l1_cache.set(key, data)
return data
# Load from database
data = self.database.get(key)
self.l2_cache.set(key, data)
self.l1_cache.set(key, data)
return data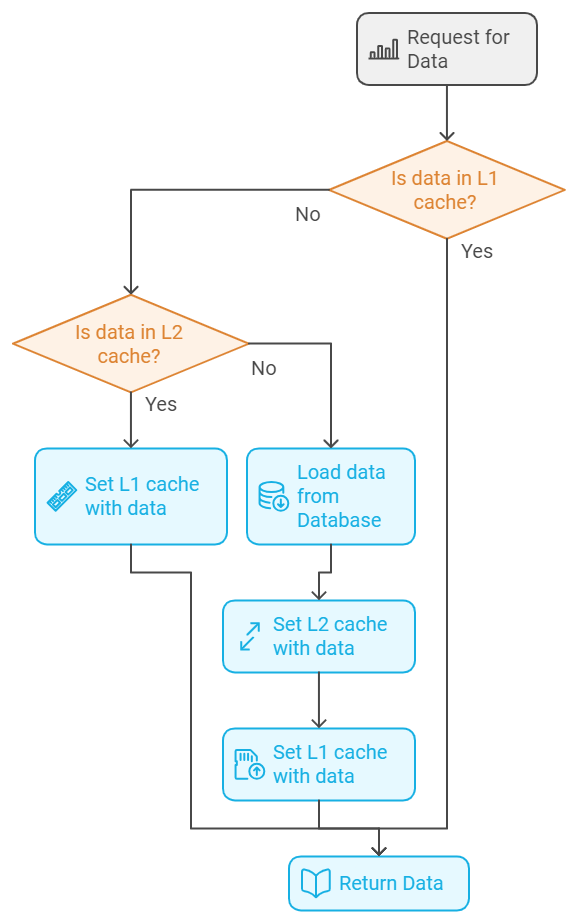
Best For: High-traffic applications requiring optimal performance
Real-World Use: E-commerce platforms, social networks
Popular Caching Solutions 🛠️
1. Redis
- In-memory data structure store
- Supports complex data types
- Built-in replication
- Used by: Instagram, GitHub, StackOverflow
2. Memcached
- Simple key-value store
- High performance
- Multi-threaded architecture
- Used by: Facebook, Twitter
3. Hazelcast
- In-memory computing platform
- Strong consistency
- Built-in clustering
- Popular in enterprise applications
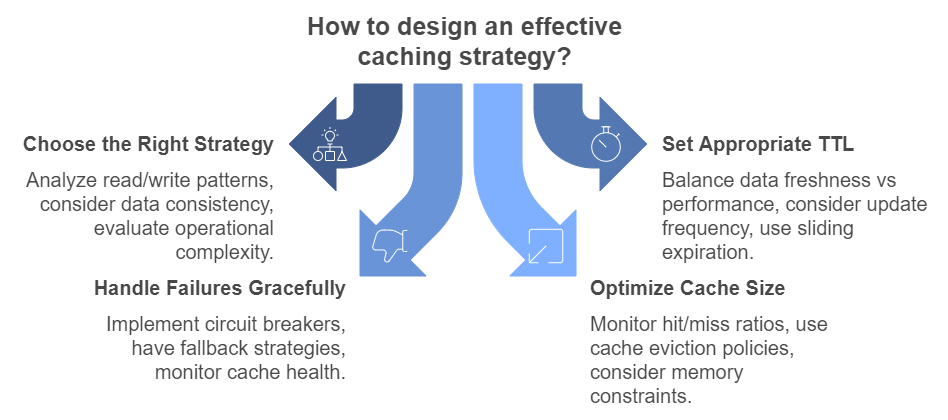
Best Practices for Implementation 📋
- Choose the Right Strategy 🎯
- Analyze your read/write patterns
- Consider data consistency requirements
- Evaluate operational complexity
- Set Appropriate TTL ⏰
- Balance data freshness vs performance
- Consider update frequency
- Use sliding expiration when appropriate
- Handle Failures Gracefully 🛡️
- Implement circuit breakers
- Have fallback strategies
- Monitor cache health
- Optimize Cache Size 📊
- Monitor hit/miss ratios
- Use cache eviction policies
- Consider memory constraints
Real-World Example: E-commerce Product Cache 🛍️
class ProductCache:
def __init__(self):
self.l1_cache = LocalCache()
self.l2_cache = RedisCache()
self.refresh_ahead = RefreshAheadCache()
async def get_product(self, product_id):
# Try L1 cache
product = self.l1_cache.get(product_id)
if product:
return self.validate_product(product)
# Try L2 cache with refresh-ahead
product = await self.l2_cache.get(product_id)
if product:
self.l1_cache.set(product_id, product)
return self.validate_product(product)
# Cache miss
product = await self.database.get_product(product_id)
await self.update_caches(product)
return product
def validate_product(self, product):
if self.is_stale(product):
asyncio.create_task(self.refresh_product(product.id))
return productFAQs 🤔
How do I choose the right caching strategy?
Consider your application’s read/write patterns, consistency requirements, and operational complexity. Cache-Aside is great for read-heavy workloads, while Write-Through is better for consistency-critical applications.
What’s the ideal cache size?
Follow the 80/20 rule: cache the 20% of data that serves 80% of requests. Monitor your hit/miss ratios and adjust accordingly.
How do I handle cache failures?
Implement circuit breakers, maintain fallback mechanisms, and always have a direct database access path. Consider using multi-level caching for better resilience.
What’s the difference between Redis and Memcached?
Redis offers more features (complex data types, persistence, replication) but requires more resources. Memcached is simpler and faster for basic key-value caching.
How do I prevent cache stampedes?
Use techniques like cache warming, sliding windows, or implement the cache-aside-lease pattern. Refresh-Ahead strategy can also help prevent stampedes.
When should I use Multi-Level Caching?
Use it when you need to balance between performance and cost, especially in high-traffic applications where reducing network calls is crucial.
Wrapping Up 🎁
Choosing the right caching strategy is crucial for application performance. Start simple with Cache-Aside or Read-Through, then evolve based on your needs. Remember to:
- Monitor cache performance
- Handle failures gracefully
- Keep cache data fresh
- Optimize based on usage patterns
For more detailed information, check out:
Happy caching! 🚀
Did you find this article helpful? Share it with your team and let me know your thoughts in the comments below!
Next: The Ultimate Guide to Distributed Transactions in 2024





